



吴川 2020-9-4
华南区技术负责人
最近由王芳在 2021-1-29进行了更新
概要
您是否遇到过想要提取图片中的HTML代码,可尝试过很多软件却依旧无法达到最佳的转换效果?不用担心,这篇文章能够帮助你解决类似的困惑。其实很多程序员和技术工作者也面临着同样的问题,为此小编特地帮大家选取了几款能够较好地完成识别并提取图片中HTML代码的软件,您不必再为四处寻找一款得心应手的软件而焦头烂额了,因为您想解决的类似问题都能够在这篇文章里找到答案,下面我们深入地了解一下具体的解决方案吧。
HTML(或HTM)又称超文本标记语言,是标准通用标记语言下的一个应用。“超文本”就是指页面内可以包含图片、链接,甚至音乐、程序等非文字元素。HTML之所以称为超文本标记语言,是因为文本中包含了所谓“超级链接”点,就是一种URL指针,通过激活(点击)它,可使浏览器方便地获取新的网页。这也是HTML获得广泛应用的最重要原因之一。
由此可见,网页的本质就是HTML,通过结合使用其他的Web技术(如:脚本语言、CGI、组件等),可以创造出功能强大的网页。因而,HTML是Web编程的基础,也就是说万维网是建立在超文本基础之上的。
了解了什么是HTML之后,下面我们就来解决如何识别并提取图片中的HTML代码的问题。

想要识别并提取图片中的HTML代码,可以使用带有OCR功能的专业软件去实现,下面小编会推荐大家几款带有OCR功能的工具,能够帮助您快速地识别并提取图片中的HTML代码,一起去了解一下吧。
都叫兽™PDF转换软件是什么?
此外,都叫兽™PDF转换软件还支持英/法/德/意/西/葡/中/韩/日等多国语言文字的转换,在OCR模式下,选择对应的识别语言,可大大提高字符识别的正确率,转换效率极高,即使是电脑初学者也能够轻松搞定。
都叫兽™PDF转换器 - 多功能的PDF转换工具 (100页免费)
多种转换 Word/Excel/PPT/Text/Image/Html/Epub
多种编辑功能 加密/解密/分割/合并/水印等。
支持OCR 从扫描的 PDF、图像和嵌入字体中提取文本
编辑/转换速度快 可同时快速编辑/转换多个文件。
支持新旧Windows Windows 11/10/8/8.1/Vista/7/XP/2K
多种转换 Word/Excel/PPT/Text/Image...
支持OCR 从扫描的 PDF、图像和嵌入字体中提取文本
支持新旧Windows Windows 11/10/8/8....
如何借助都叫兽™PDF转换软件识别并提取图片中的HTML代码
都叫兽™PDF转换软件共有两种功能,一种是可以满足对PDF格式文件的基本编辑需求;另一种功能是可以将PDF格式文件转换成其他常用的格式文件,下面我们看一下如何启用都叫兽™PDF转换软件的OCR功能达到识别HTML代码的目的。
操作过程非常简单,具体步骤如下:
步骤1:下载并运行都叫兽™PDF转换软件,选择“转换PDF”选项并进入。

步骤2:进入操作页面后,选择顶部菜单栏最右侧的“OCR”选项按钮。接下来通过“添加文件”按钮将需要识别并提取HTML代码的图片文件(JPG/PNG/BMP格式)导入到都叫兽™PDF转换软件当中。
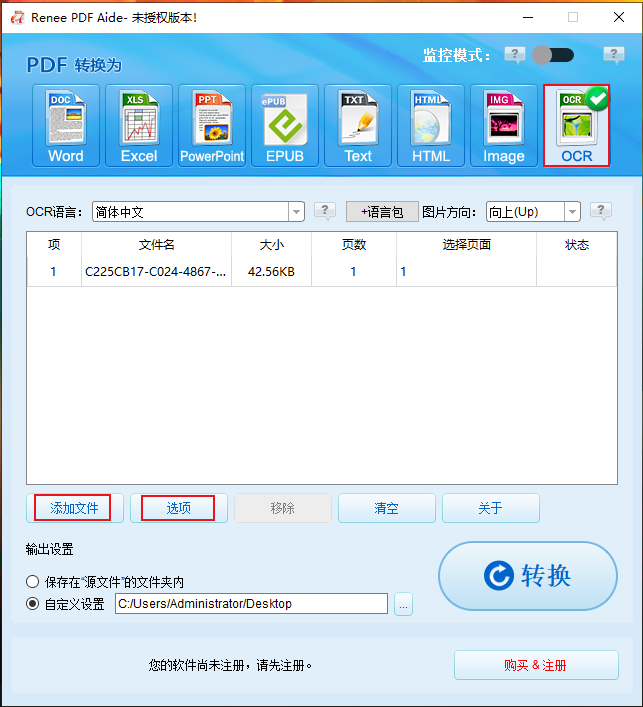
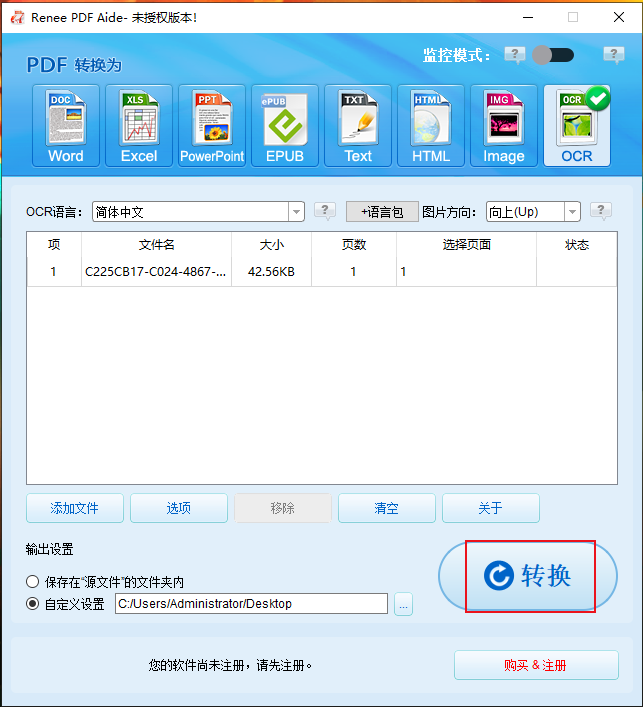
步骤3:设置完成后点击右侧“转换”按钮,即可开始执行将图片文件里面的HTML代码识别并保存为TXT格式的文本文件,非常的方便快捷。之后您就可以直接将“.txt”文件的后缀名改为“.html”,获得一个HTML文件;也可以复制TXT文件中的代码到别的文件或网站中使用。
Google Docs是一款免费的在线格式转换或编辑工具,具备OCR功能,能够实现对图像内容或PDF文件的文本识别。下面我们一起学习一下使用Google Docs识别并提取图片中的HTML代码的操作方法。
具体操作步骤如下:
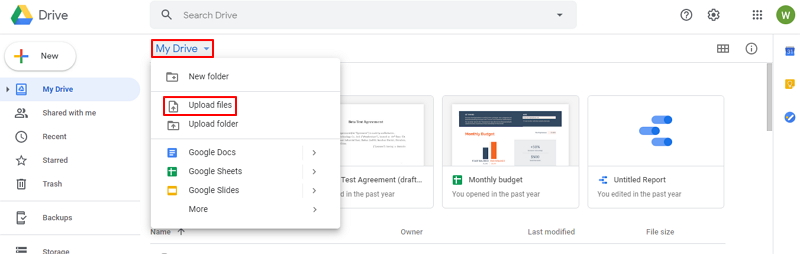
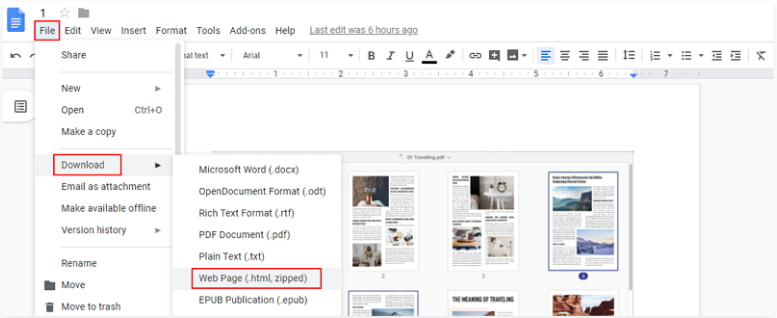
步骤1:使用谷歌账户登录到您的Google Drive里,之后找到“My Drive”-“Upload files”(上传文件)按钮,将需要识别并提取HTML代码的图片上传到Google Drive里。
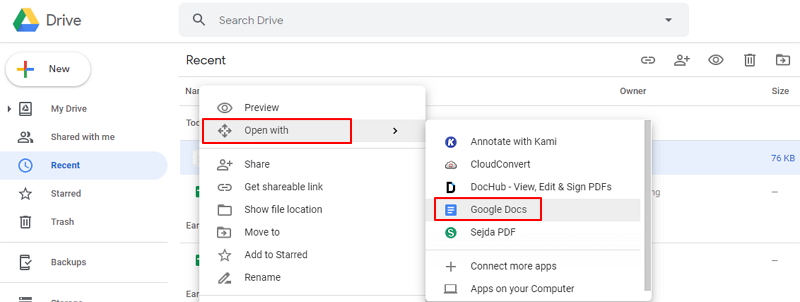
步骤2:右键点击上传的图片文件,之后选择“Open With”(通过…打开)-“Google Docs”。这时,文件加载的过程中会出现一个工作表的图标,即为Google正在使用OCR技术识别您的图片内容并将其打开。
步骤3:接下来,回到顶部功能菜单栏里找到“File”(文件)-“Download”(下载)选择将图片文件存储为HTML格式或其他您需要的格式,之后就能将提取出来的HTML代码保存到本地电脑中了。
FreeFileConvert是一款免费的多功能在线格式转换工具,具备多种媒体形式的格式转换工具,比如音频转换器、视频转换器、图像转换器、文档转换器、电子书转换器、字体转换器、计量单位转换器等等。此外,针对PDF格式的文件还提供了诸如压缩、分割、加密、解密等常规的编辑功能。与一般的在线格式转换工具不同,FreeFileConvert具备OCR功能,这能够提高格式转换时的内容准确率。下面我们看一下如何使用该在线工具来识别并提取图片中的HTML代码。
具体操作步骤如下:
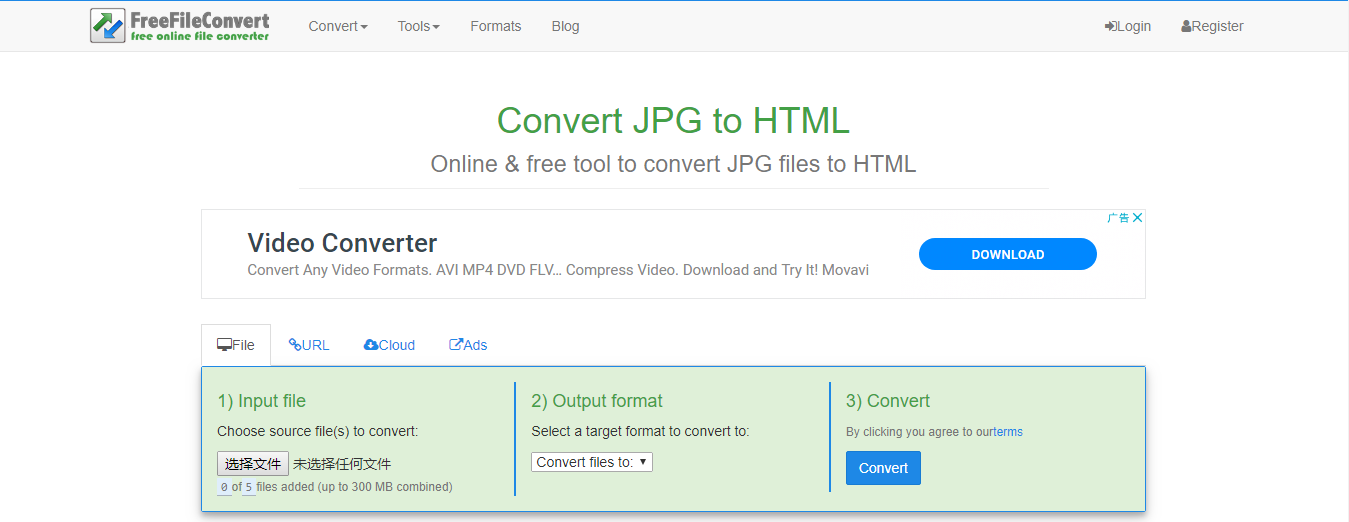
在浏览器里打开FreeFileConvert工具的在线操作网址:https://www.freefileconvert.com/jpg-html,接下来找到格式转换的操作框,在“Input file”(输入文件)操作栏里点击“选择文件”按钮,将需要提取HTML代码的图片导入到该网页服务器当中(注:该工具最多同时转换5个文件,最大文件大小不超过300MB)。之后在“Output format”(输出格式)操作栏里点击“Convert files to”(转换成)选择“html”格式。设置完成后,点击“Convert”(转换)按钮,即可开始执行将图片文件转换成HTML格式文件的命令,非常的方便。
上文中,小编向大家介绍了三种能够识别并提取图片中的HTML代码的工具,下面针对这三种工具的使用感受做一个简单的总结,希望能帮助您选择到一个适合自己的操作方法。
从功能配备上考量:
文中介绍的三种方法都具备OCR技术,正因为具备该技术,才使得这三种方式在识别和提取图片中的HTML代码的时候更加有效。虽然同为格式转换工具,但是在功能配置上略有不同,其中都叫兽™PDF转换软件对比于其他两种工具的优势点在于操作过程更加稳定,您可以在离线状态下完成图片内容的识别和提取,而不用担心中途失败的问题。除了可以识别并提取图片中的HTML代码,都叫兽™PDF转换软件还支持PDF的格式转换与基础编辑,功能较为全面。
从安全性上考量:
使用FreeFileConvert在线工具和Google Docs同属于在线操作工具,需要将图片文件上传到相应的网络服务器当中,存在一定的安全隐患。而这两者不同之处在于,Google Docs由强大的Google公司背书,文件安全性方面更加让人放心一些,但是这两者的安全性均不如都叫兽™PDF转换软件,因为该软件的所有操作都在本地完成,支持离线操作,不会发生数据被拦截或窃取的情况。
从转换结果上考量:
都叫兽™PDF转换软件采用了更为先进的OCR技术,支持多国语言的识别,转换结果会更加优秀;而Google Docs和FreeFileConvert两者虽然也都具备OCR技术,但是通过Google Docs打开的文件,只会保留文件的文本,不会保留文件原来的排版样式,这是它的一个不足之处。如果您需要保留源文件的排版样式,建议优先使用另外两种方式。至于FreeFileConvert,它支持的 OCR语言不多,因此如果您需要识别多种语言的文件,那么该方法的识别结果会差一些。
大家可以根据上面的分析,结合自己的实际需求来进行选择和使用。

 粤公网安备 44070302000281号
粤公网安备 44070302000281号
