



钟艳萍 2026-6-30
首席客服专员
最近由刘涛在 2026-6-30进行了更新
概要
全面解析字符编码失败的技术原因,提供系统性方法修复PDF转换乱码错误。本文深度评测专业桌面OCR软件、原生办公应用及云端平台,帮你找到恢复文档可读性的最有效方案,轻松解决PDF转换乱码难题。

想象一下,当你打开转换后的Word文档时,看到的不是清晰可读的文本,而是散乱的符号、空心方块或完全无法理解的乱码。这不仅仅是个随机故障——这是PDF提取文本时发生的典型 字体渲染和字符编码失败 ,也就是常见的PDF转换乱码问题。大多数转换工具依赖于PDF中嵌入的文本和字体信息。如果这些数据丢失、损坏或映射错误,最终就会得到无法阅读的输出。
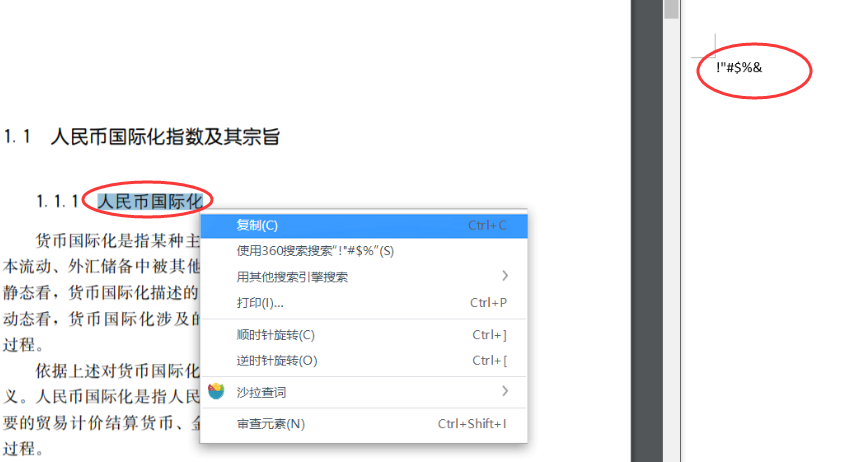
主要的技术原因包括:
- 缺少系统字体: PDF引用了未嵌入的字体,且你的电脑中没有这些字体。转换工具会替换为通用字体,导致字符错位或PDF转换乱码。
- CMap表损坏或非标准: PDF内部将字符代码映射到字形的过程受损,或使用了自定义编码,这在旧版或多语言文档中尤为常见,极易引发PDF转换乱码。
- 自定义字体和连字: 使用专有字体或特殊连字创建的PDF在转换时经常会损坏,因为软件无法重建原始布局,从而导致PDF转换乱码。
- 扫描件OCR识别效果差: 如果你的PDF是基于图像的,基础的OCR识别可能会误读字符,导致出现随机符号或空白方块,造成PDF转换乱码。
为了确定你的具体情况,在选择修复方法前,请参考下方的诊断表。
| PDF类型 | 现象描述 | 最佳修复方法 | 推荐方案 |
|---|---|---|---|
扫描/基于图像 |
文本无法选择;看起来像照片。 |
OCR模式A(识别图片中的文本) |
任何标准OCR工具 |
带有嵌入字体的原生PDF |
文本可以选择,但渲染为乱码符号或豆腐块(PDF转换乱码)。 |
OCR模式B(识别内置字体) |
都叫兽™ PDF转换 |
损坏/受损 |
错误信息、内容丢失或崩溃。 |
文件修复 |
专业修复工具 |
如果你的PDF看起来正常,但转换后变成了乱码,问题就出在字体层。在这种情况下, OCR模式B 是你最可靠的解决方案,能有效修复PDF转换乱码。
都叫兽™ PDF转换是一款功能全面的Windows桌面PDF工具,专为解决这些复杂的提取问题而设计,同时确保你的文档保留在本地,保障隐私安全。

为什么都叫兽™ PDF转换在修复PDF转换乱码方面脱颖而出:
- OCR模式B: 软件不从损坏的字体表中读取,而是将嵌入字体视为图像,然后运行精确的OCR生成干净、可编辑的文本——完全绕过编码错误,解决PDF转换乱码。
- 100%本地处理: 所有工作都在你的电脑上完成,敏感文件绝不会离开你的设备。
- 快速批量转换: 每分钟可转换多达80页,并一次性处理多个文件。
- 多功能输出: 可导出为Word、Excel、CSV、Markdown、HTML、Text、ePub等多种格式。
- XFA表单兼容性: 能处理来自银行和政府机构的特殊PDF,这是大多数转换工具无法处理的。
都叫兽™ PDF转换还包含优化、修复、合并、拆分和加密功能。但在修复PDF转换乱码和“豆腐块”时,OCR模式B是你的必备工具。
按照以下步骤,将PDF文本恢复为干净、可编辑的状态,轻松修复PDF转换乱码:
步骤 1 :打开并选择模块
启动都叫兽™ PDF转换。在主界面上,点击 “转换PDF” 选项卡开始转换过程。


步骤 2 :添加乱码PDF文件
点击 “添加文件” 导入一个或多个PDF——支持批量转换。
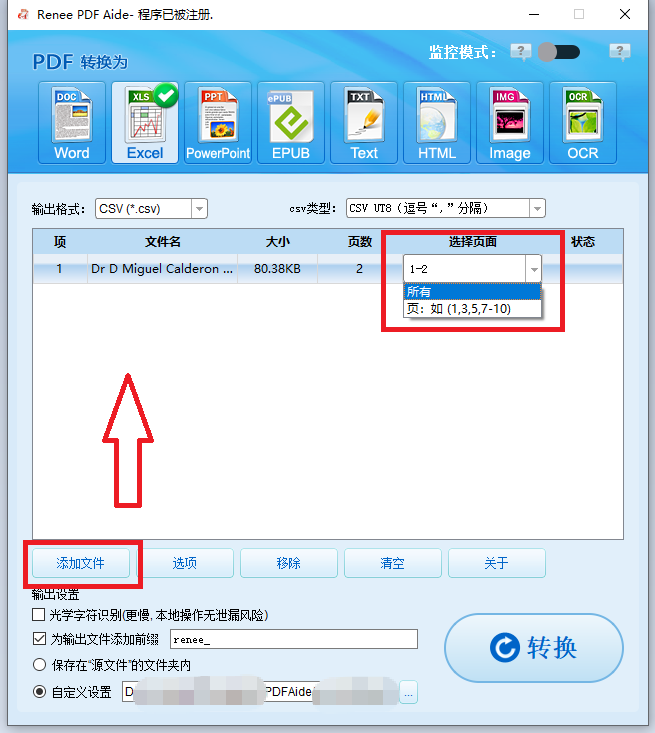
步骤 3 :选择输出格式和选项
从顶部栏选择所需的输出格式(如 Word 或 Excel )。点击 “选项” 进行额外设置——例如在Excel中将所有页面合并到一个工作表,或调整Word的导出首选项。
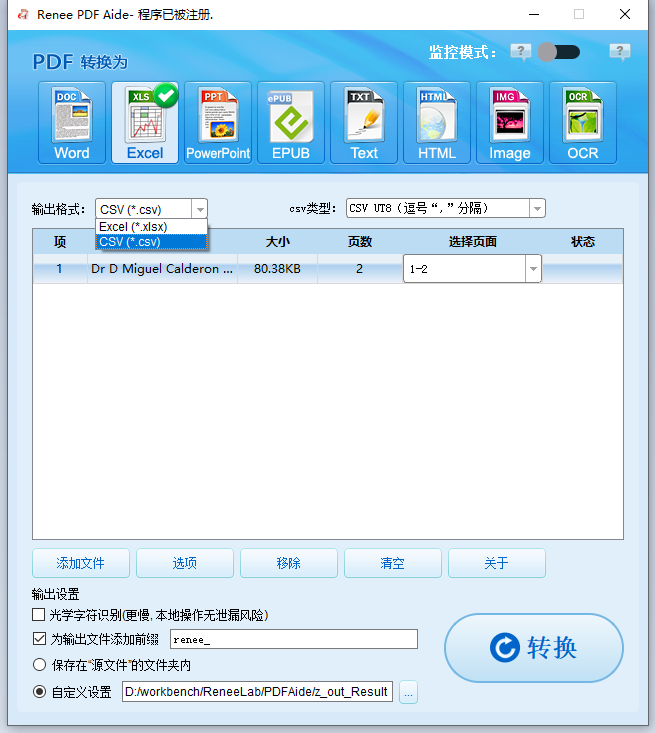
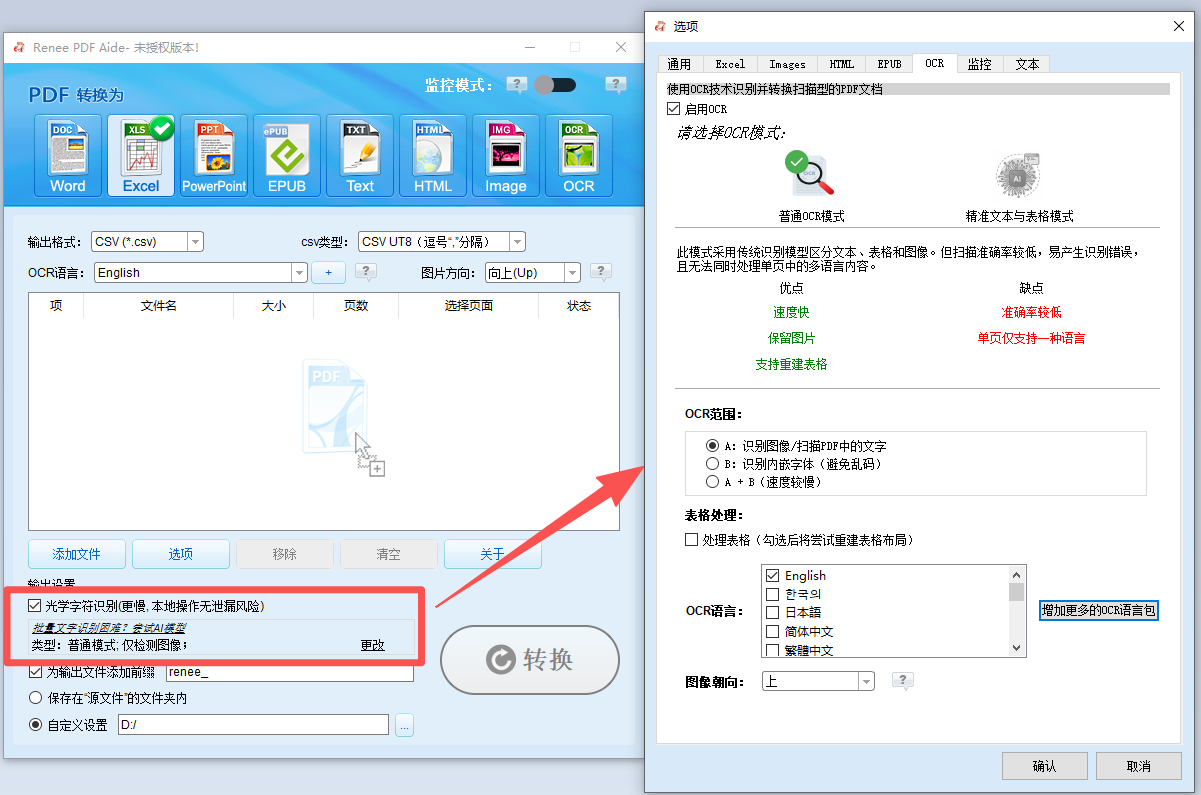
步骤 4 :启用OCR并选择模式B(关键步骤)
勾选 “启用OCR” 框。在OCR面板中,选择 模式B:识别内置字体(避免乱码) 。此模式将嵌入字体视为图像并应用OCR提取干净文本,绕过字体编码问题,彻底修复PDF转换乱码。确保从下拉菜单中选择正确的文档语言,以获得最佳识别准确率。
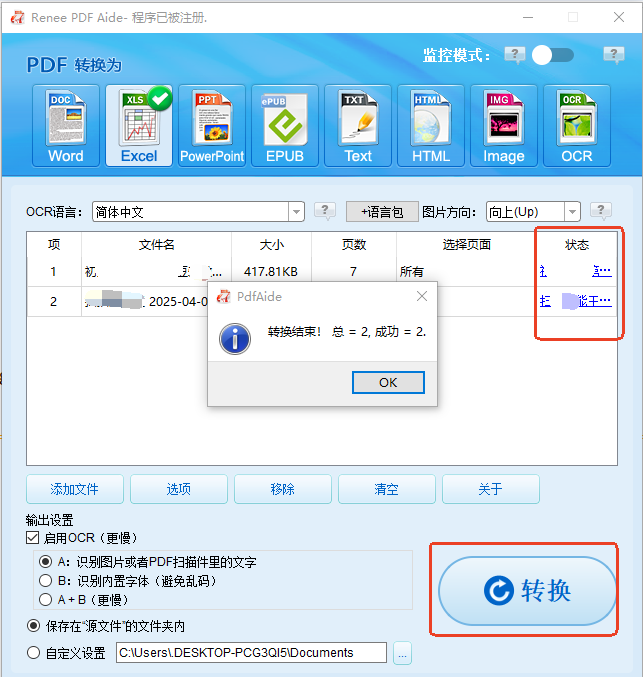
步骤 5 :转换并获取
点击 “转换” 开始处理。完成后,你会看到一个包含转换结果的摘要窗口。在 “状态” 列中,点击文件链接打开全新清理、完全可编辑的文档。
都叫兽™ PDF转换是解决字体编码错误、修复PDF转换乱码最可靠和安全的方法,但对于简单或不敏感的文档,还有其他选项。以下是它们的对比:
Smallpdf、iLovePDF和Zamzar等在线服务因快速、免安装转换而受欢迎。虽然方便,但这些工具依赖于标准PDF解析——它们读取的是导致乱码输出的同一个损坏文本层。因此,转换后的文件通常看起来和原来一样乱,或者服务可能直接失败,无法修复PDF转换乱码。
隐私是另一个问题:将机密文档上传到第三方服务器意味着放弃对数据的控制。加上每日限制、文件大小限制以及缺乏高级字体识别功能,在线工具最适合用于非敏感的简单PDF。
优点:
- 无需安装
- 界面简单,适合日常使用
- 小文件提供免费层级
缺点:
- 无针对乱码的特定修复;重用同一损坏文本层
- 上传的文档会离开你的设备——存在隐私风险
- 有文件大小和每日使用限制
- 无法处理复杂的字体编码
如果你有Microsoft Word或Adobe Acrobat,可以尝试它们内置的PDF转换功能。 Adobe Acrobat Pro 可以将PDF导出为Word,但如果字体缺失或编码损坏,它通常会用矩形或通用符号替换字符。它不会将字体转换为图像或重新进行OCR。 Microsoft Word 可以打开PDF并尝试重建它们,但在处理复杂布局、缺失字体或非标准编码时很吃力,通常会导致文本混乱或丢失,难以修复PDF转换乱码。
优点:
- 如已安装则无需额外软件
- 适用于标准、编写良好的PDF
- 熟悉的界面
缺点:
- 无专用的“避免乱码”OCR模式
- 字体替换会为缺失的字形创建豆腐块
- Word的PDF导入严重依赖源格式,处理表格/多语言内容时经常失败
- 无法修复损坏的编码表
如何尝试(结果可能因文件而异):
Adobe Acrobat Pro: 打开PDF,然后转到“文件”>“导出到”>“Microsoft Word”>“Word文档”。
Microsoft Word: 打开Word,选择“文件”>“打开”,然后选择你的PDF。Word会提示你进行转换。

浏览器打印为PDF变通方法: 在浏览器中打开PDF,按 Ctrl+P (macOS上为 Cmd+P ),并保存为新的PDF。然后在Word中打开这个新PDF。
如果转换后的文本依然乱码,你最好的选择是使用完全绕过文本层的工具——带有OCR模式B的都叫兽™ PDF转换,彻底修复PDF转换乱码。
原生工具适用于PDF格式良好时的快速、直接转换。但对于顽固的字体编码错误,它们就无能为力了,无法修复PDF转换乱码。
以下是快速对比,帮助你选择最适合自己需求的方法来修复PDF转换乱码:
| 方法 | 乱码字体准确率 | 隐私(本地/云端) | 批量支持 | 成本 |
|---|---|---|---|---|
都叫兽™ PDF转换(模式B) |
高 – 完全绕过编码错误,修复PDF转换乱码 |
完全本地 |
是,一键批量 |
付费(提供免费试用) |
在线转换工具 |
低 – 重用损坏的文本层 |
云端(隐私风险) |
有限或订阅制 |
免费增值/订阅制 |
Adobe Acrobat / MS Word |
中 – 适用于编码良好的PDF |
本地(如已安装) |
取决于产品 |
付费(或包含在Office中) |
对于任何转换后显示豆腐块、乱码符号或无法阅读文本的PDF,都叫兽™ PDF转换能提供最准确的结果——同时确保你的文件安全,完美修复PDF转换乱码。
OCR模式B究竟是如何修复PDF转换乱码和“豆腐块”的?
OCR模式B完全绕过损坏的文本层。它不读取损坏的字体映射表,而是将每一页渲染为高分辨率图像并应用OCR提取文本。此过程从头开始重建内容,消除由编码错误引起的豆腐块和混乱符号,彻底修复PDF转换乱码。
如何判断我的PDF文件该用模式A、模式B还是模式A+B?
参考上方的诊断表。对于扫描/基于图像的PDF(文本无法选择),使用 模式A 。对于可以选择文本但转换后出现乱码的原生PDF,使用 模式B 以修复PDF转换乱码。 模式A+B 尝试两种方法,如果你不确定或文件包含扫描页和嵌入字体页的混合,它很有用,尽管速度较慢。
OCR模式B支持包含复杂字符集的多语言PDF吗?
是的。在OCR面板中,你可以从下拉列表中选择文档的主要语言。对于多语言PDF,选择主要语言或最接近的匹配项。模式B将使用适当的语言模型来提高识别准确率,支持中文、阿拉伯文、天城文等多种文字。
应用模式B后转换出的文本依然乱码该怎么办?
首先,仔细检查你是否在OCR设置中选择了正确的文档语言。如果问题仍然存在,请验证PDF是否能在阅读器中正确打开——如果不能,文件可能已损坏,应先进行修复。你也可以尝试模式A+B进行更深层的扫描以修复PDF转换乱码,尽管这需要更长的时间。如果只有少数符号不正确,在输出文件中手动编辑可能是最快的修复方法。


 粤公网安备 44070302000281号
粤公网安备 44070302000281号

用户评论
留下评论