



概要
本文深入解析 python pdf转docx 的多种实现方案,全面盘点 pdf2docx、PyMuPDF 等主流 Python 库及专业桌面工具。重点分享批量处理脚本、OCR 识别技术及自动化文件夹监控方案,助你轻松构建稳定高效的文档处理工作流。


| 问题类型 | 常见原因 | 预检 / 诊断 |
|---|---|---|
扫描版 PDF |
无可选中文本 |
打开 PDF 并尝试选中文本;如果无法选中,则需要使用 OCR |
复杂表格/排版 |
pdf2docx 缺乏排版引擎 |
先转换一页,检查是否有列错位 |
嵌入字体 / 乱码 |
字体子集化或非标准编码 |
检查 DOCX 中是否有 □ 或随机符号 |
大批量转换崩溃 |
内存或依赖冲突 |
先用 5-10 个文件测试;密切关注内存使用情况 |

| 方案 | 最适用场景 | 主要局限 |
|---|---|---|
pdf2docx |
原生 PDF 的快速转换 |
复杂排版处理能力弱;无 OCR |
PyMuPDF + python-docx |
完全掌控与自定义提取逻辑 |
需要大量代码来重建排版 |
pdfplumber |
以表格为主的 PDF |
无 DOCX 输出;仅支持文本提取 |
Pandoc |
可脚本化的管道;多格式工作流 |
PDF 转 DOCX 的质量取决于 LaTeX/PDF 阅读器 |
LibreOffice CLI |
批量自动化;无头转换 |
排版还原度不稳定;无 OCR |
| 功能 | 支持情况 |
|---|---|
直接 PDF 转 DOCX |
是 |
OCR |
否 |
嵌入字体 |
部分支持 |
复杂排版 |
一般 |
自动化 |
是 |
XFA 表单 |
否 |
| 功能 | 支持情况 |
|---|---|
直接 PDF 转 DOCX |
否(需手动编码) |
OCR |
否(需外部 OCR) |
嵌入字体 |
仅读取 |
复杂排版 |
高控制度,需手动处理 |
自动化 |
优秀 |
XFA 表单 |
否 |
| 功能 | 支持情况 |
|---|---|
直接 PDF 转 DOCX |
否 |
OCR |
否 |
嵌入字体 |
否 |
复杂排版 |
擅长表格 |
自动化 |
是 |
XFA 表单 |
否 |
| 功能 | 支持情况 |
|---|---|
直接 PDF 转 DOCX |
是(通过 LaTeX) |
OCR |
否 |
嵌入字体 |
否 |
复杂排版 |
有限 |
自动化 |
优秀 |
XFA 表单 |
否 |
| 功能 | 支持情况 |
|---|---|
直接 PDF 转 DOCX |
是 |
OCR |
否 |
嵌入字体 |
部分支持 |
复杂排版 |
一般 |
自动化 |
优秀 |
XFA 表单 |
否 |

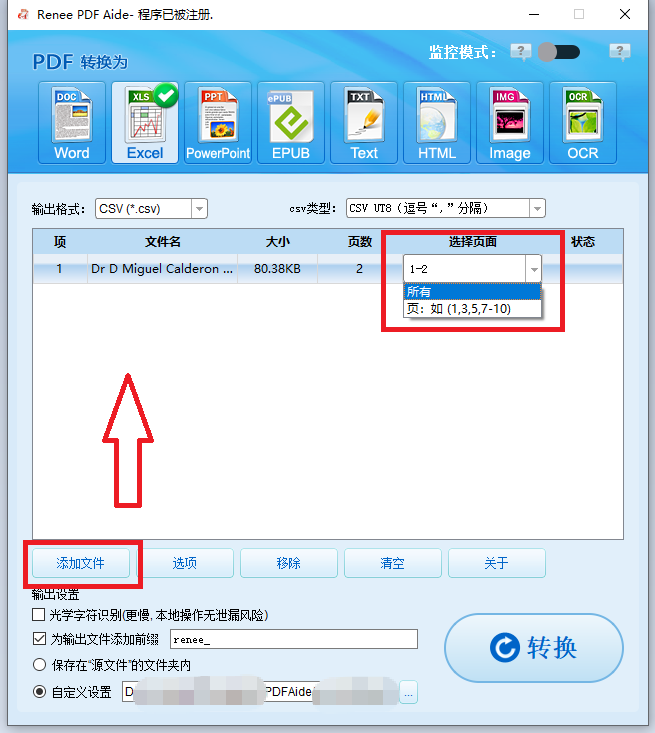
多种转换 Word/Excel/PPT/Text/Image/Html/Epub
多种编辑功能 加密/解密/分割/合并/水印等。
支持OCR 从扫描的 PDF、图像和嵌入字体中提取文本
编辑/转换速度快 可同时快速编辑/转换多个文件。
支持新旧Windows Windows 11/10/8/8.1/Vista/7/XP/2K
多种转换 Word/Excel/PPT/Text/Image...
支持OCR 从扫描的 PDF、图像和嵌入字体中提取文本
支持新旧Windows Windows 11/10/8/8....
核心优势包括

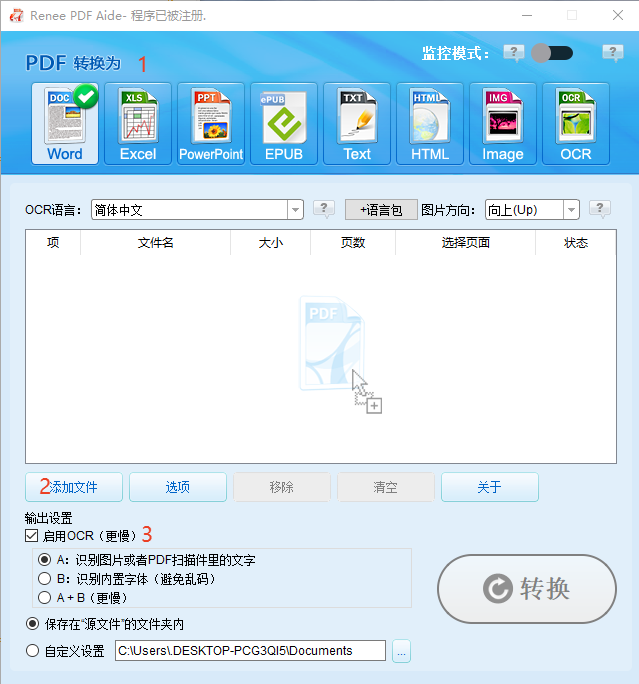
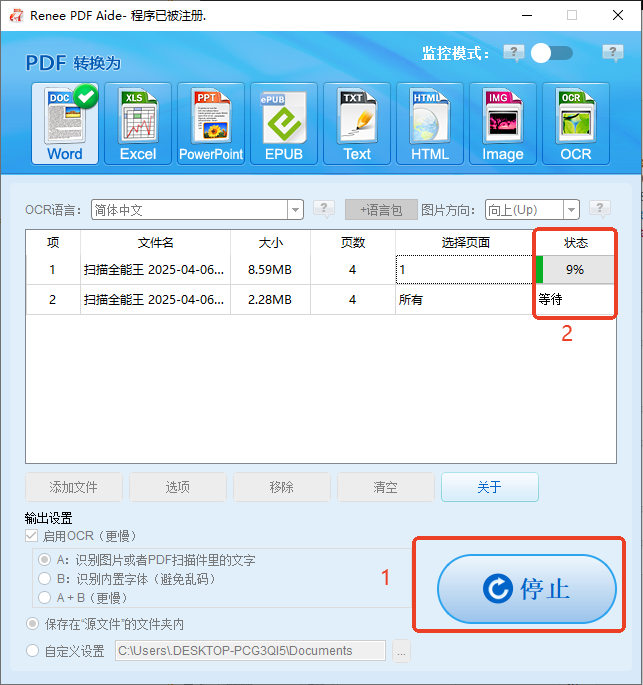
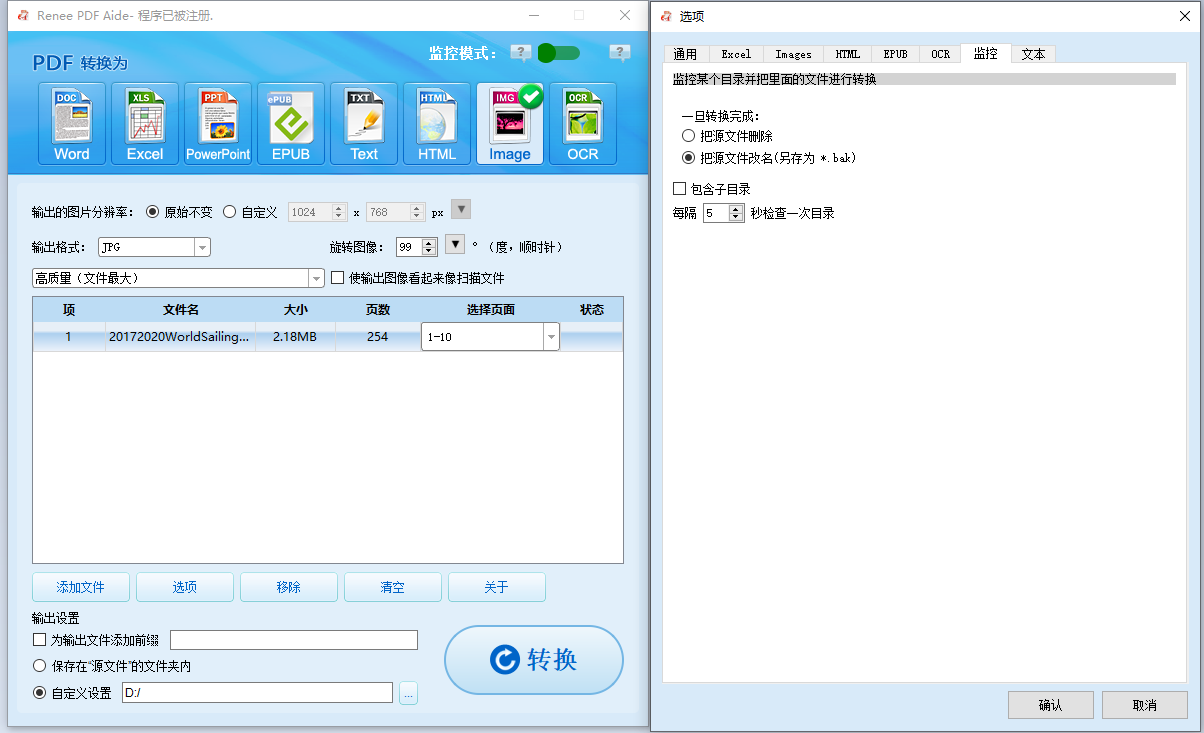
多种转换 Word/Excel/PPT/Text/Image/Html/Epub
多种编辑功能 加密/解密/分割/合并/水印等。
支持OCR 从扫描的 PDF、图像和嵌入字体中提取文本
编辑/转换速度快 可同时快速编辑/转换多个文件。
支持新旧Windows Windows 11/10/8/8.1/Vista/7/XP/2K
多种转换 Word/Excel/PPT/Text/Image...
支持OCR 从扫描的 PDF、图像和嵌入字体中提取文本
支持新旧Windows Windows 11/10/8/8....
操作步骤
pip install pymupdf python-docx watchdog
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
python pdf_to_docx_automate.py
局限性
- 完全的代码控制与自定义
- 处理简单原生 PDF 免费使用
- 轻松集成到现有 Python 管道
缺点:
- 扫描文档无内置 OCR
- 复杂表格和图像经常错位
- 需要外部工具进行定时执行
- 针对不同 PDF 排版需要大量调试
| 使用场景 | 推荐工具 |
|---|---|
快速测试 1-2 个简单 PDF |
Python pdf2docx 脚本 |
扫描版 PDF 或复杂排版 |
带 OCR 的 都叫兽™ PDF转换 |
批量转换(50 个以上文件) |
都叫兽™ PDF转换(批量 + 监控模式) |
定时夜间转换 |
都叫兽™ PDF转换 监控模式 |
完全掌控代码 + 简单 PDF |
PyMuPDF + watchdog 自定义脚本 |
都叫兽™ PDF转换 能处理 Python 脚本无法读取的扫描版 PDF 吗?
为什么 pdf2docx 会丢失表格格式或列对齐?
都叫兽™ PDF转换 的最大批量或页数限制是多少?
用 Python 或 都叫兽™ PDF转换 能把加密 PDF 转为 DOCX 吗?
都叫兽™ PDF转换 支持处理 XFA 表单(如银行/政府 PDF)吗?
多种转换 Word/Excel/PPT/Text/Image/Html/Epub
多种编辑功能 加密/解密/分割/合并/水印等。
支持OCR 从扫描的 PDF、图像和嵌入字体中提取文本
编辑/转换速度快 可同时快速编辑/转换多个文件。
支持新旧Windows Windows 11/10/8/8.1/Vista/7/XP/2K
多种转换 Word/Excel/PPT/Text/Image...
支持OCR 从扫描的 PDF、图像和嵌入字体中提取文本
支持新旧Windows Windows 11/10/8/8....



 粤公网安备 44070302000281号
粤公网安备 44070302000281号

用户评论
留下评论