



吴川 2025-10-28
华南区技术负责人
最近由王芳在 2025-10-28进行了更新
概要
想高效提取PDF中的表格?本文为你盘点2025年最实用的免费工具与前沿AI方案,助你轻松将PDF表格精准、安全地转换为Excel、CSV、Markdown等多种格式。无论你是财务人员、数据分析师还是科研工作者,这些方法都能大幅提升工作效率,告别手动复制粘贴的烦恼!


是否厌倦了手动从PDF中提取表格?2025年,随着数十亿份PDF文档在商业与科研领域流通,你并不孤单——许多数据从业者都将PDF表格提取视为一大痛点。无论是50页的财务报告还是扫描版发票,将数据干净利落地导入 Excel 、 CSV 或 Markdown 本不该如此费力。
好消息是,如今先进的AI与工具让这一切变得轻而易举。本终极指南将深入探讨最佳方法:从注重隐私的本地Windows桌面软件 都叫兽™PDF转换软件 ,到专为复杂版式设计的AI智能方案,助你彻底释放数据价值!

这些基于桌面的解决方案让你直接在电脑上提取PDF表格,确保速度、隐私与精准度,非常适合日常需求,如分析销售数据或整理研究统计资料。
若追求功能、隐私与易用性的最佳平衡,我们强烈推荐 都叫兽™PDF转换软件 。它不仅是一款普通PDF转换器,更是一套专为复杂数据提取任务设计的综合性桌面解决方案。
得益于内置的先进OCR(光学字符识别)技术,它在 提取原生PDF与扫描版PDF中的表格 方面尤为出色。其一大优势在于多功能性,可直接将PDF表格转换为:
- Excel(*.xlsx)
- CSV(*.csv) (非常适合数据库与数据分析)
- Markdown (适用于AI训练数据或技术文档)
- TXT 文件
- 可编辑的 Word 文档
- ……以及其他多种格式。
由于软件在本地运行,你的敏感文档永远不会离开电脑,确保数据完全私密。
都叫兽™PDF转换软件操作简便,转换速度高达 80页/分钟 ,支持将PDF转换为 Excel/CSV 、 Word 、 PowerPoint 、 ePub 、 文本(txt/markdown) 、 HTML 、 JPG 、 TIFF 等多种格式。
此外,该软件还集成了PDF优化、修复及加密等多种功能。尽管功能丰富,其界面却 简洁直观、易于上手 。都叫兽™PDF转换软件采用 先进OCR技术 ,可将扫描版PDF和图片转换为可编辑格式,并支持 一键批量转换 ,兼顾效率、安全与免费体验。

使用都叫兽™PDF转换软件提取表格的步骤
① 安装都叫兽™PDF转换软件后打开,点击“ 转换PDF ”。

② 点击“ 添加文件 ”按钮导入待转换的PDF文件。软件支持 批量转换 ,可同时导入多个文件。添加后,文件信息将显示在转换列表中。点击“ 选定页面 ”列表可设置转换范围。
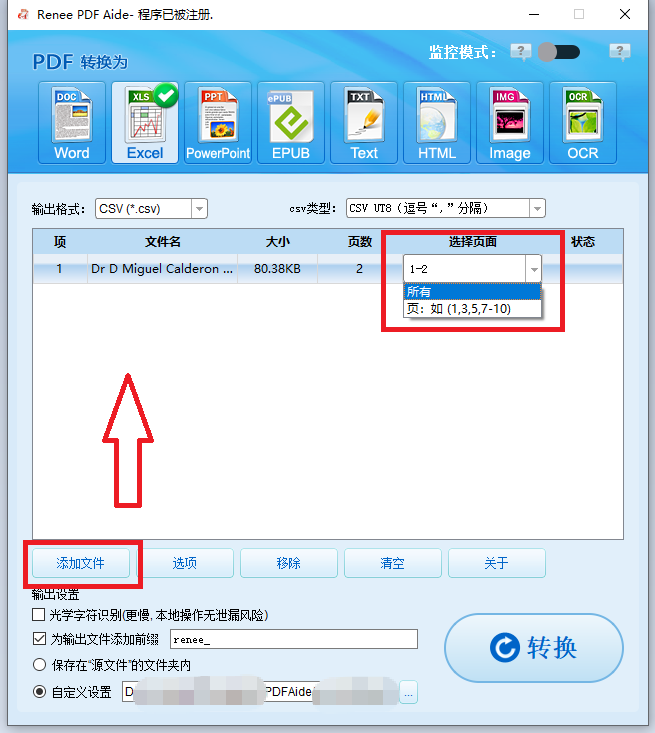
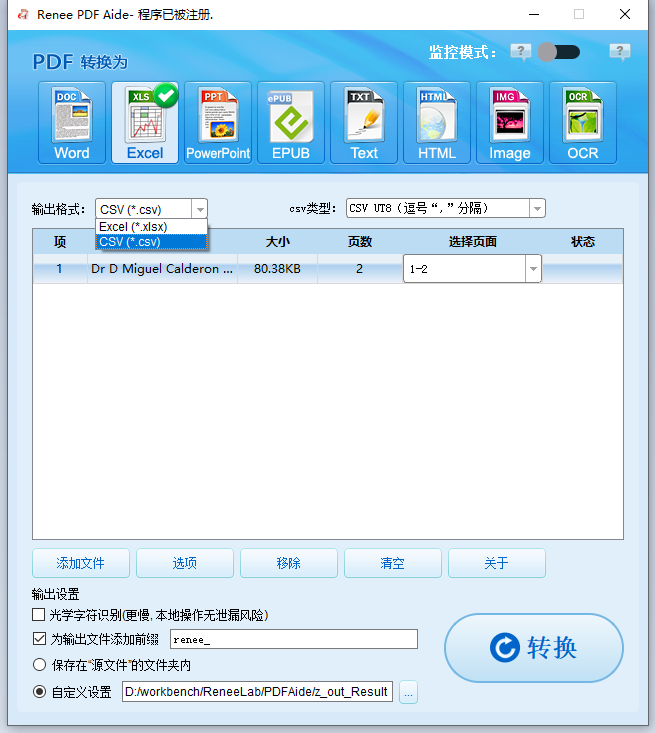
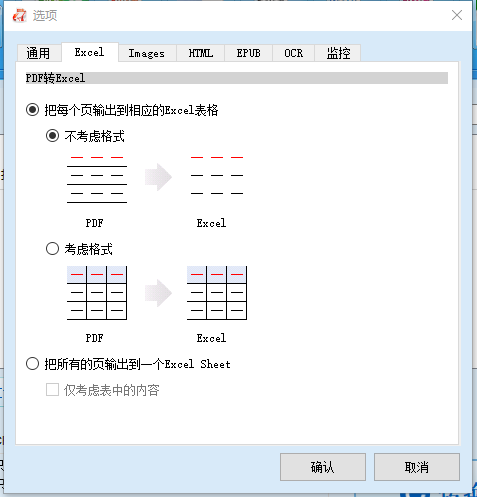
③ 选择输出格式 。在顶部栏选择目标格式。提取表格时,通常选择Excel或CSV(位于Excel标签页);若需转换为TXT,可在TXT标签页选择 Markdown 或 TXT 。
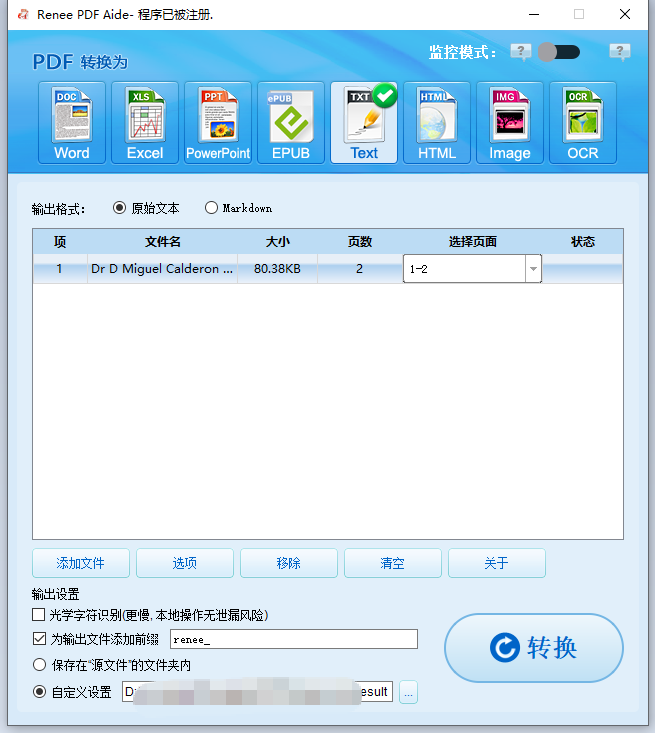
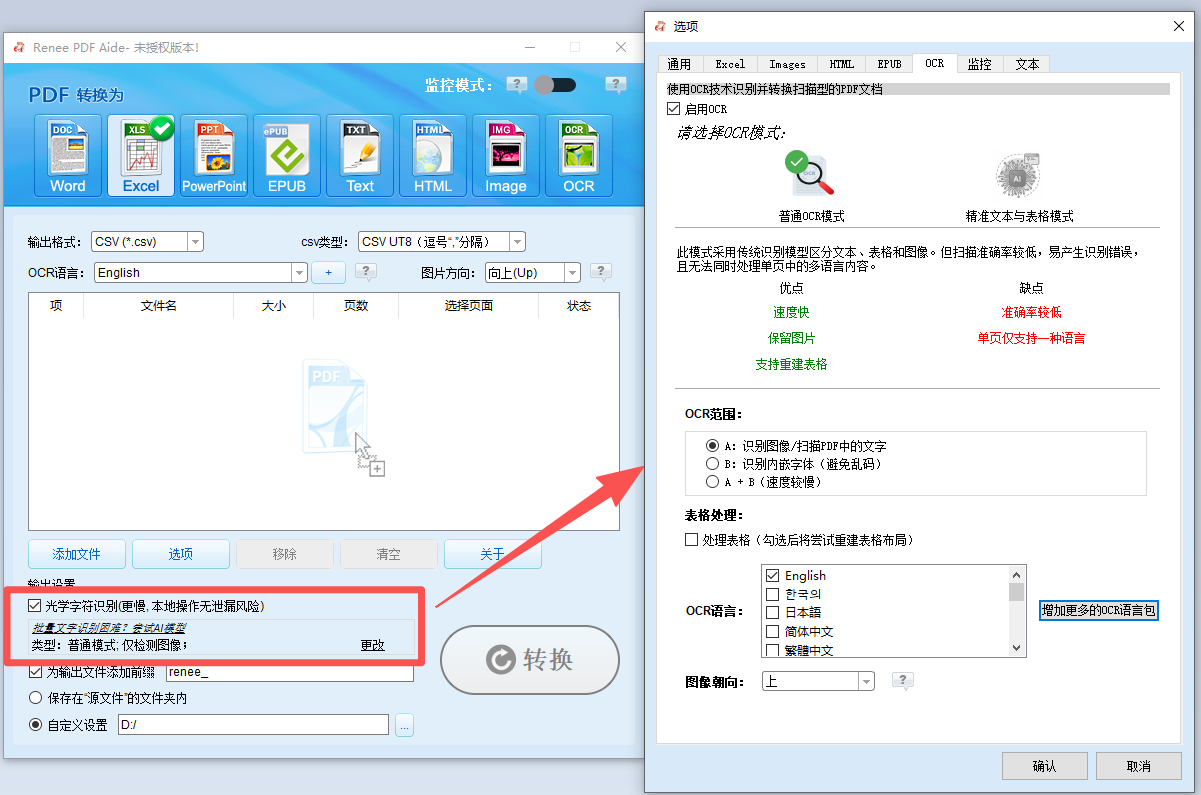
④ 若PDF为扫描件(即图片形式),请勾选“ 启用OCR ”;若为原生PDF(含可选文本),则可跳过此步。
OCR模式说明:
A:识别图片或PDF扫描件中的文字: 此模式假设PDF页面上的文字为图片/扫描图像,并通过OCR(选择对应语言可提升识别效果)识别并输出文字。
B:识别内嵌字体(避免乱码): 此模式假设PDF页面使用了嵌入字体,程序会先将这些字体转为图像,再通过OCR(选择对应语言可提升识别效果)识别并输出文字。
A+B(较慢): 程序自动判断文件中的字体是图片还是嵌入式PDF字体,再进行转换输出。此模式耗时较长,转换速度较慢。
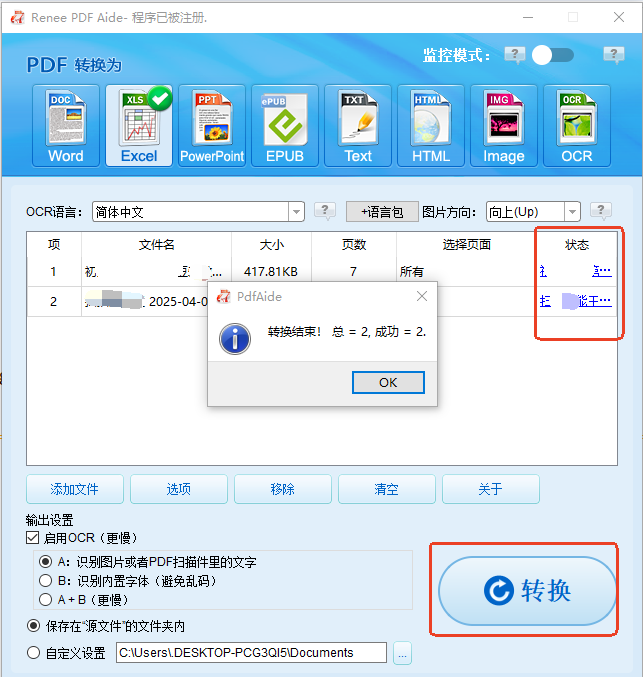
⑤ 点击“ 转换 ”按钮。转换完成后,系统将提示已转换文件总数及成功数量。此时,你的PDF表格已变为完全可编辑格式。点击“状态”列中的链接即可查看结果文件。
都叫兽™PDF转换软件为你提供安全、快速且高精度的表格提取方案,轻松应对各类复杂任务。
若预算为零且表格结构相对简单, Tabula 是一款出色的开源工具。它是一款简洁免费的应用程序,可在本地电脑(Windows、macOS或Linux)运行,因此同样具备 数据隐私保障 。
优点:
- 完全免费且开源。
- 本地运行,确保100%数据隐私。
- 界面简洁,支持可视化框选表格区域。
- 可导出为CSV格式,通用性强。
缺点:
- 不支持扫描版(图像型)PDF。
- 面对复杂表格、合并单元格或特殊版式时可能表现不佳。
- 需在系统中预先安装Java。
- 已停止维护,发现的Bug可能不会修复。
使用Tabula提取表格的步骤:
1. 下载、安装并运行Tabula(程序将在浏览器中打开,但仍在本地运行)。
2. 解压下载的zip文件。
3. 进入刚解压的文件夹,运行其中的“Tabula”程序。
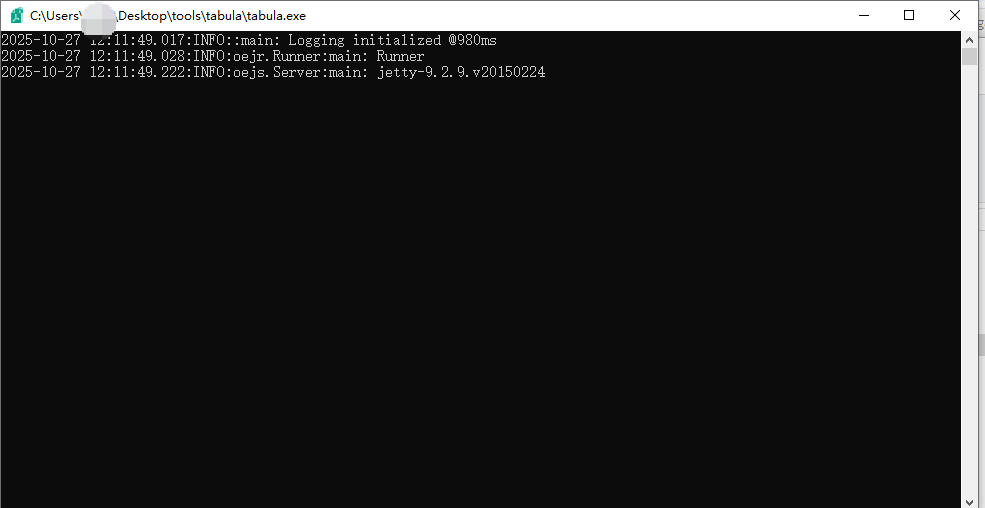
4. 浏览器将自动打开。若未自动打开,请手动访问 http://localhost:8080 。
5. 点击“Browse”上传PDF文件,然后点击“Import”。
6. PDF加载后,用鼠标拖拽框选需要提取的表格区域。
7. 点击“ Preview & Export Extracted Data ”。
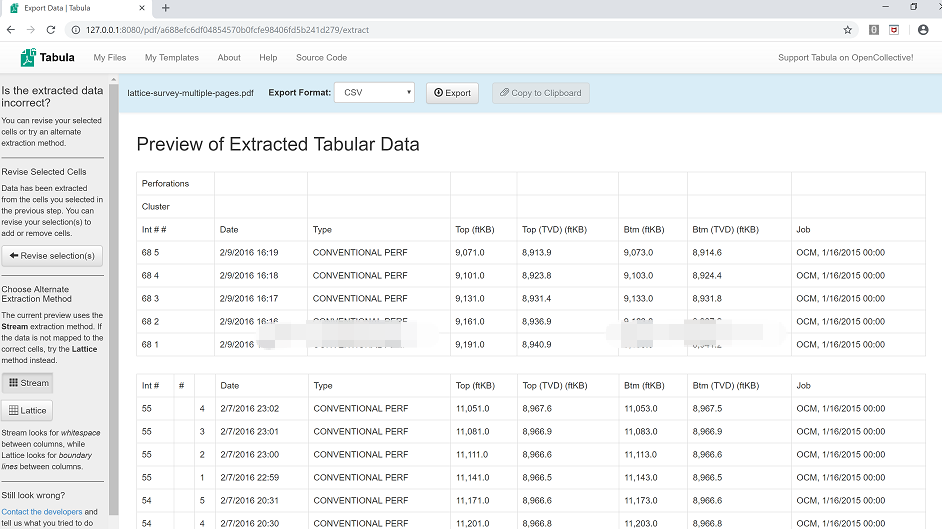
8. 预览数据,确认无误后选择导出格式(如CSV),点击“ Export ”即可。
Tabula是处理简单原生PDF表格的绝佳入门工具。若文档为扫描件或表格版式复杂,则可能需要更强大的解决方案。
对于已深度使用Adobe生态的专业人士而言, Adobe Acrobat 专业版 是行业标杆级工具。表格提取仅是其庞大功能集的一小部分。它几乎能处理任何PDF,包括 复杂版式和扫描文档 (借助其高质量OCR技术)。
其“导出PDF”功能可将PDF表格直接转换为格式化的 Excel(XLSX)工作簿 或 Word文档 ,通常能高度还原原始样式、字体与布局。这是企业环境中追求精准度与Adobe产品集成度的首选,但需支付高昂的 订阅费用 。
优点:
- 对原生PDF和扫描PDF均具备极高识别准确率。
- 导出至Excel时格式保留效果极佳。
- 属于完整的PDF编辑套件(可编辑文字、图片等)。
- 由知名大厂提供支持,值得信赖。
缺点:
- 价格昂贵(需按月或按年订阅)。
- 若 仅需 提取表格,则功能过剩。
- 程序庞大,可能占用较多系统资源。
使用Adobe Acrobat Pro提取表格的步骤:
1. 在Adobe Acrobat Pro中打开PDF文件。
2. 在右侧工具面板中找到并选择“导出PDF”。
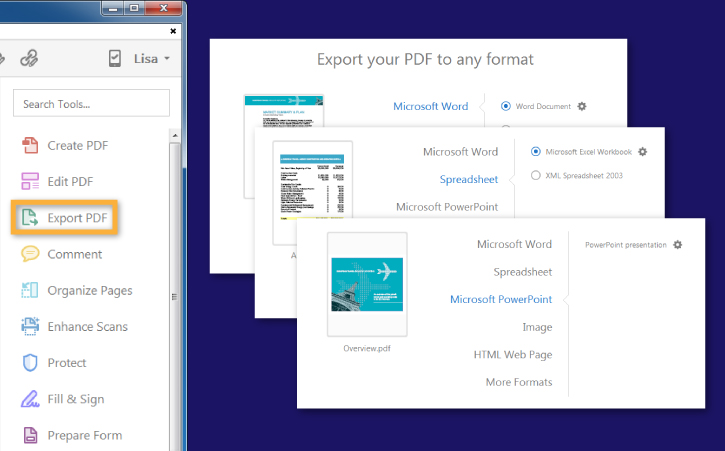
1. 选择“电子表格”作为导出格式,再选择“Microsoft Excel工作簿”。
2. Acrobat将自动识别表格。若为扫描文件,可点击设置齿轮图标调整OCR参数。
3. 点击“导出”,选择保存位置即可生成Excel文件。
若你已拥有Acrobat Pro,它无疑是出色的选择;若尚未购买,其高昂价格很难仅因表格提取功能而被接受。
如果你的PDF其实只是一组纸质文件的照片,那就是 扫描版PDF ,普通提取工具将无能为力。此时,专业的 光学字符识别(OCR) 工具如 ABBYY FineReader 便大显身手。尽管Acrobat和都叫兽™PDF转换软件也具备优秀OCR能力,但FineReader被公认为专精于文档识别的市场领导者。它利用先进AI分析页面布局,识别文字与数字,并 从图像中高精度重建复杂表格 ,特别适合处理老旧报告或发票等高价值数据。
优点:
- OCR识别准确率行业领先,尤其擅长处理低质量或模糊扫描件。
- 重建复杂表格结构的能力极强。
- 支持语言种类极为丰富。
- 可批量处理数千页文档。
缺点:
- 专业版定价较高。
- 对普通用户而言,配置完美识别结果可能较为复杂。
- 因OCR分析强度高,处理速度相对较慢。
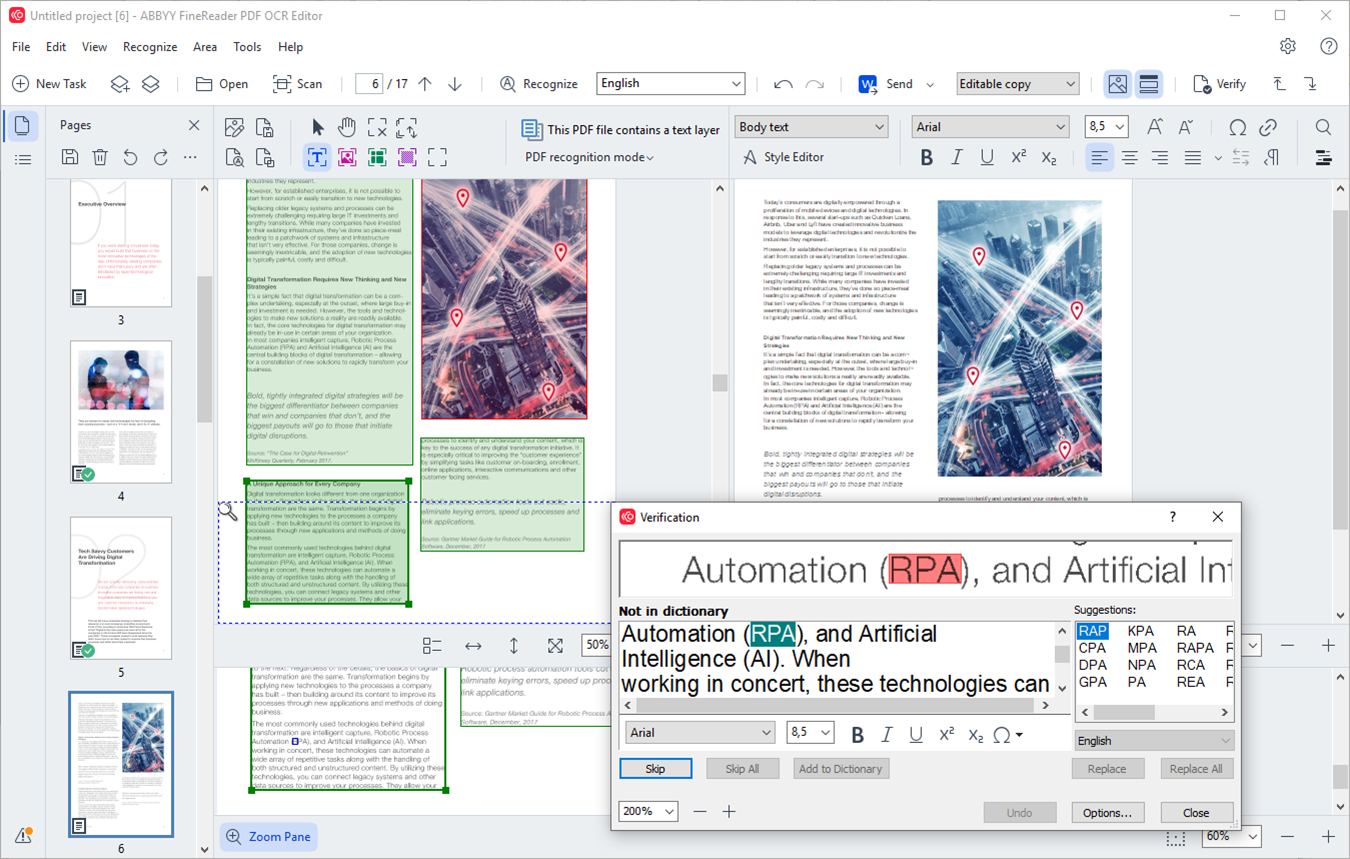
使用ABBYY FineReader提取表格的步骤:
1. 在ABBYY FineReader中打开扫描版PDF。
2. 软件将自动对文档执行OCR识别。
3. 导航至包含表格的页面。
4. 使用“表格”工具检查(必要时修正)识别出的表格区域。
5. 表格识别无误后,使用主“导出”功能将其发送至Excel或其他格式。
对于精度要求极高的复杂扫描文档,ABBYY是无可匹敌的专业工具。若处理的是简单且非敏感文件,可考虑下文介绍的在线转换器。
有时你只是急需数据,又不想安装任何软件。此时, 在线PDF转Excel工具 如 SmallPDF 和 ILovePDF 便派上用场。操作极其简单:访问网站,拖放PDF文件,等待转换完成,下载Excel结果即可。这些工具非常适合处理 简单、非机密的原生PDF ,速度快、跨设备可用,且通常每日提供有限次数的免费转换。但最大隐患在于 隐私安全 ——你必须将文档上传至第三方服务器,这对敏感的商业或个人数据构成重大风险。
优点:
- 操作极其简单——只需拖放即可。
- 无需安装,任何带浏览器的设备均可使用。
- 处理简单文件时速度极快。
- 多数服务提供免费额度,适合偶尔使用。
缺点:
- 存在重大隐私风险:必须将文件上传至第三方服务器。
- 面对复杂表格或扫描PDF时常会失败(除非付费启用OCR)。
- 免费版通常限制文件大小、页数或每日使用次数。
- 需稳定的网络连接。
在线转换器适合临时处理非敏感文件。但若你的PDF是 扫描图像 ,或包含 复杂的多栏表格 而在线工具难以应对,此时 AI智能助手 如 Copilot 、 ChatGPT 或 Grok 便大有用武之地。
📊 PDF转Markdown表格工具对比
| PDF输入支持 | 扫描图像OCR | 免费版限制 | 付费版优势 | |
|---|---|---|---|---|
| Copilot | ✅ 仅支持截图(不支持直接上传PDF) | ✅ 通过图像输入实现OCR | ⚠️ 每条消息仅限一张图;不支持PDF上传 | ✅ 图像输入无限制;处理更快;格式还原度更高 |
| ChatGPT | ✅ 支持PDF与图像输入(仅限GPT-4o) | ✅ OCR与版面解析能力强 | ⚠️ GPT-3.5版本;不支持图像/PDF | ✅ GPT-4o支持图像/PDF上传;OCR与格式还原能力更强 |
| Grok | ✅ 支持截图或粘贴内容 | ✅ Grok 3版OCR能力提升 | ✅ x.com/app上Grok 3免费使用,但有配额限制 | ✅ Grok 3/4高级版解锁扩展内存(128K tokens)、语音访问、图像模型(Imagine)及AI伙伴(Ani & Valentine);取代Think与DeepSearch功能 |
这些工具能结合OCR(光学字符识别)与大模型AI,分析扫描文档或截图,识别表格结构,并 生成整洁、可编辑的Markdown表格 。尤其适用于以下场景:
- 你正在处理图像型PDF或表格截图。
- 你需要保留格式,但不想使用Excel。
- 你想将表格直接嵌入基于Markdown的文档或网站中。
使用AI工具提取表格的步骤:
1. 从PDF或图像中截取或裁剪出表格区域。
2. 将图片上传至支持OCR与Markdown生成的AI助手(如支持图像输入的Copilot)。
3. 向助手发出指令:“请将此表格转换为Markdown格式。”
4. 检查并复制生成的Markdown表格到你的文档或编辑器中。
当传统转换器失效或你需要更精细的格式控制时,这些AI工具尤为有用。此外,许多工具无需将文件上传至第三方服务器——它们可在本地或安全环境中运行。
对于数据科学家、开发者或需要 自动化处理数百份PDF表格 的用户,最强大的方法是编程。借助 Python库 如 Tabula-py (Tabula工具的封装)或 Camelot ,你可以编写脚本批量处理整个文件夹的文档。此方法提供精细控制:可指定坐标、处理跨页表格,并在保存为CSV、数据库或JSON前对数据进行程序化清洗。 此方法不适合初学者 ,需具备扎实的Python知识,但对于大规模数据项目而言,这是终极解决方案。
优点:
- 功能强大且高度可定制。
- 完美适用于大规模批量自动化处理。
- 可轻松集成到更大数据分析流程中。
- 多数库免费且开源。
缺点:
- 需具备较强的编程与技术能力。
- 针对特定PDF版式,调试与配置耗时较长。
- PDF版式稍有变动就可能导致脚本失效。
使用Python提取表格的概念步骤:
1. 安装Python及所需库(例如: pip install tabula-py )。
2. 编写Python脚本导入相关库。
3. 使用类似 tabula.read_pdf("your_file.pdf", pages="all") 的函数将表格读入数据结构。
4. 编写额外代码处理数据并保存为CSV等目标格式。
5. 在终端中运行脚本。
尽管功能强大,自行编写提取器仍是一项重大工程。在动手之前,不妨先了解为何某些PDF比其他PDF更难处理。
是否曾打开一份看似表格的PDF,却发现任何工具都无法读取?你可能遇到了 XFA(XML表单架构)表单 。这类PDF并非“普通”PDF,而是基于XML的动态表单(通常由Adobe LiveCycle创建),允许用户填写字段。由于内容是动态生成的,大多数标准PDF提取工具 无法识别其中数据 ,只能看到空白表单。通常需借助专业软件(如Adobe Acrobat或 都叫兽™PDF转换软件 )专门解析并“扁平化”XFA表单后,才能提取数据。
为什么不能直接从PDF复制粘贴表格?
复制粘贴只能获取文字内容,无法保留 结构信息 。PDF格式并不以网格形式存储数据,而是将文本片段按特定X/Y坐标放置。粘贴后,所有行列对齐信息都会丢失,最终得到一堆混乱的文字。
提取扫描版(图像型)PDF表格的最佳方法是什么?
必须使用具备 光学字符识别(OCR) 功能的工具。图像型PDF本质上只是文字的照片;OCR会扫描图像,识别字符,并将其重建为可编辑的数字文本。 都叫兽™PDF转换软件 、Adobe Acrobat和ABBYY FineReader均内置强大的OCR引擎,专为此类任务设计。
在线PDF表格提取工具安全吗?
这取决于你的数据内容。对于非敏感信息(如公开报告),通常可以接受。但你 必须将文件上传至第三方服务器 。我们强烈建议 切勿 使用在线工具处理包含财务数据、个人信息或其他机密内容的文档。
能否一次性从一份PDF中提取多个表格?
可以,大多数高质量工具均支持此功能。 都叫兽™PDF转换软件 可转换整个文档(或指定页面),并自动提取所有识别到的表格。高级工具如Python脚本甚至能一次性处理数千份文档中的表格。
原生PDF与扫描PDF有何区别?
原生PDF 是数字生成的(例如从Word“另存为PDF”),可直接选中并高亮文本。 扫描PDF (或图像PDF)由扫描仪或拍照生成,本质上是一张图片,无法选中单个文字,因为文件仅识别为图像。
我的PDF表格包含合并单元格和复杂表头,哪种工具最合适?
这类场景正是免费工具如Tabula容易失效的地方。你需要具备版面分析能力的高级转换器。 Adobe Acrobat 和 都叫兽™PDF转换软件 在转换至Excel时均能出色识别并保留合并单元格等复杂结构,确保数据准确性。




 粤公网安备 44070302000281号
粤公网安备 44070302000281号

用户评论
留下评论